



AI-Box离线DeepSeekR1助手
简介
本项目基于泰山派RK3566,可本地运行DeepSeek/Qwen/Gemini大模型,无需网络
简介:本项目基于泰山派RK3566,可本地运行DeepSeek/Qwen/Gemini大模型,无需网络开源协议
:GPL 3.0
描述
项目简介
本项目基于泰山派RK3566构建,是一个可以离线本地运行的AI大模型盒子,并通过语音控制灯光获取天气等等,这是一个无需联网、无需API、无需付费的纯本地大模型案例,支持主流小参数大模型部署DeepSeek-R1/Qwen/Gemini等等。
本项目不含泰山派开发板成本大致为25.5元,主要费用在于屏幕4.5元,驻极体麦克风3.6元。PCB及3D均支持免费打样。
本项目不涉及设备树,无需编译Linux系统,大大简化操作,但需具备一定的Linux知识。
项目功能
- ✅离线本地对话DeepSeek-R1/Qwen/Gemini等开源模型(无需联网、无需付费)
- ✅离线实时天气获取
- ✅语音控制灯光
- ✅电池供电
- ✅引出串口,可充当语音模块
硬件参数
- 本设计基于泰山派RK3566,内置WIFI功能,通过AP模式遥控
- 屏幕支持0.96寸SSD1306/SSD1315驱动OLED显示屏,可显示表情、对话反馈、天气等相关信息
- 选用IP5306充放一体电源芯片,提供最大2.1A输出,为泰山派供电
- 选用AHT10高精度温湿度传感器,可实时获取温度、湿度信息。
- 选用驻极体麦克风,可实时获取环境音频信息。
- 选用8R1W喇叭,提供音频输出。
- 采用MOS管开关电路,支持驱动较大功率LED灯板。
- 采用防反接电路,可任选Type-C接口供电。
软件参数
- 系统基于Ubuntu20.04
- 环境为Python3.8
- 软件框架为Vosk+Ollama+espeak-ng
- 模型权重为DeepSeek-R1 1.5B/Qwen2 0.5B
开发文档
嘉立创EDA-教育与开源文档中心原理解析
篇幅有限,这里仅讲解部分关键电路和程序,详细说明请查看开发文档
本项目提供了完整的说明及源码,并不局限于现有功能,您可以基于现有框架进行二
次开发,丰富AI助手的功能。
硬件设计
本项目电路由以下部分组成,电源电路、泰山派IO拓展口,防反接电路,开关电路,模块及拓展接口实现
电源电路:

供电:本项目采用IP5306锂电池充放一体芯片,可提供最大2.1A电流输出。

充电接口:TypeC接口
泰山派拓展IO:
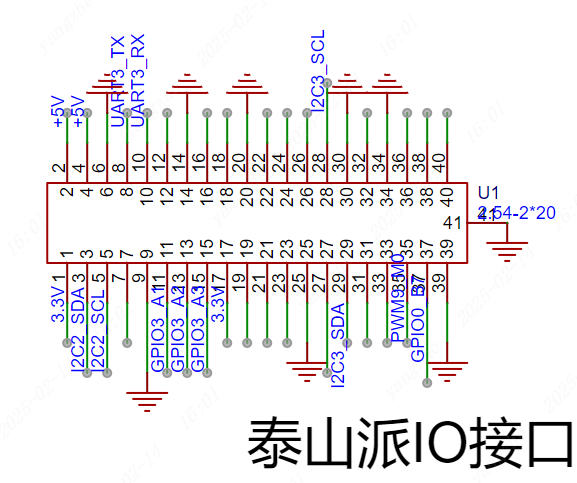
拓展IO:功能实现依赖于泰山派提供的IO口控制,这里为需要使用的引脚做好定义
防反接电路:
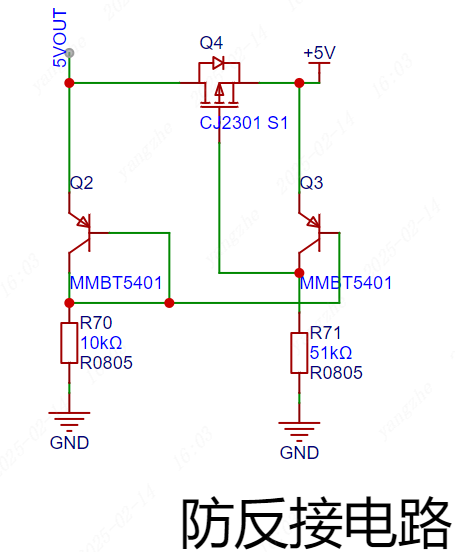
防反接:由于泰山派的DC-DC 3.3V对输入电压有较高要求,输入电压不能低于4.5V,所以这里采用MOS管和三极管实现防反接,而不是二极管。
开关电路
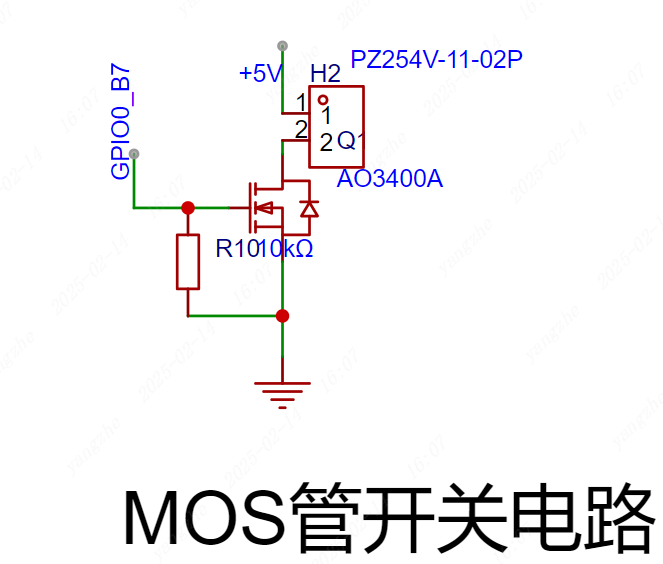
开关控制:在电路中还设计了一个MOS驱动的开关电路,帮助驱动较大电流的LED。
拓展接口及按键
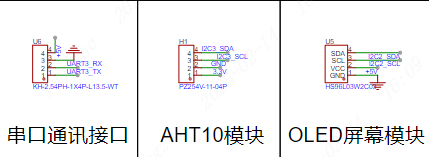
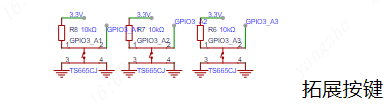
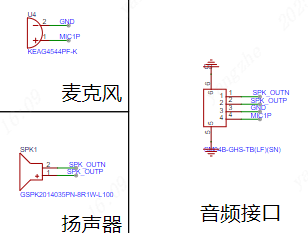
拓展接口:拓展引出UART串口,方便充当离线语言模块对接其他主控使用。
拓展模块:模块上使用OLED模块和AHT10模块,再通过音频接口引出麦克风和扬声器。
按键:引出3个按键,用于与屏幕交互。
软件代码
本项目基于Linux系统环境及其余软件包,单独使用代码无法运行,还需按照在线文档提供的教程进行环境部署。
完整的项目程序放在了附件,可直接使用,但使用前仍需要配置环境
4.7 程序编写
程序编写时可以根据自己需求进行修改,这里我们主要以语音识别和语音合成为例,进行程序编写
这里我们只讲解大模型对话测试代码,涉及大模型和OLED屏幕交互,IIC协议通讯和多线程任务。
注意事项
-
1.注意代码的保存格式,如果是gbk格式,务必在代码头部添加以下内容
# -*- coding: gbk -*-,确保Python正确识别编码格式 -
2.Python代码必须注意代码缩进和格式,如果缩进出现问题会导致程序无法正常运行
软件流程图
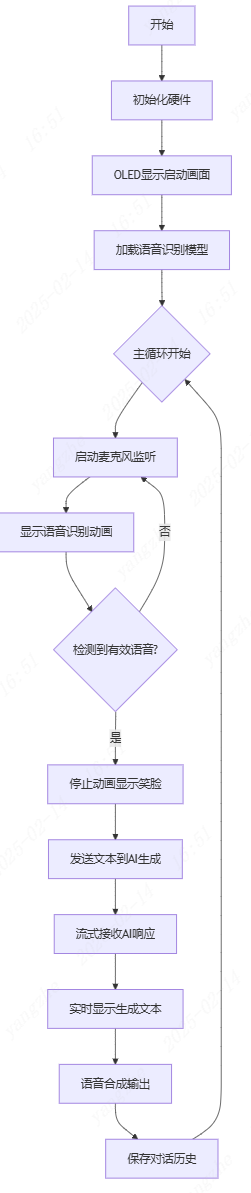
导入库文件
import time # 导入时间模块,用于控制延时
import vosk # 导入 Vosk 语音识别库
import json # 导入 JSON 解析库
import subprocess # 用于调用外部进程(如语音合成)
import ollama # 导入 Ollama,用于聊天 AI 处理
import asyncio # 导入 asyncio 以支持异步操作
import pyaudio # 导入 PyAudio 处理音频输入
import threading # 导入多线程模块
import re # 导入正则表达式模块,用于文本处理
from concurrent.futures import ThreadPoolExecutor # 用于异步任务的线程池
from board import * # 导入 board 库,用于 I2C 设备的引脚定义
import busio # 用于 I2C 通信
from PIL import Image, ImageDraw, ImageFont # 用于处理 OLED 显示图像
import adafruit_ssd1306 # 用于控制 SSD1306 OLED 屏幕
一切开始前先导入我们需要使用的pip库
定义变量
# 选择合适的字体
font_path = "/usr/share/fonts/truetype/noto/NotoSansCJK-Regular.ttc" # OLED 屏幕显示的字体路径
font = ImageFont.truetype(font_path, 16) # 设置字体大小适应屏幕
# 初始化 I2C 设备
i2c = busio.I2C(I2C2_SCL, I2C2_SDA) # 通过 I2C2_SCL 和 I2C2_SDA 初始化 I2C 通信
disp = adafruit_ssd1306.SSD1306_I2C(128, 64, i2c) # 通过 I2C 初始化 128x64 分辨率的 OLED 屏幕
# 清空屏幕
disp.fill(0)
disp.show()
# 获取屏幕宽高
width = disp.width
height = disp.height
# 创建一个空白图像用于绘制
image = Image.new("1", (width, height))
draw = ImageDraw.Draw(image)
# 设置 Vosk 语音识别模型路径,根据自己的路径设置
model_path = "/home/linaro/vosk-model-small-cn-0.22"
model = vosk.Model(model_path) # 加载 Vosk 语音识别模型
recognizer = vosk.KaldiRecognizer(model, 16000) # 以 16kHz 采样率初始化语音识别器
# 记录会话历史
conversation_history = [
{"role": "system", "content": "你是嘉立创EDA-小嘉,是一个运行在泰山派上的离线本地大模型语音助手。"},
]
MAX_HISTORY_LENGTH = 1 # 限制会话历史的最大条数
asr_running = False # 语音识别时的动画状态控制变量
这里还需要定义一些模型路径,字符路径等变量,这里为了避免内存超出,MAX_HISTORY_LENGTH限制会话最多保存1条,如果你设备内存或虚拟内存足够,可以增加。
OLED文本显示函数
def show_on_oled(text):
draw.rectangle((0, 0, width, height), outline=0, fill=0) # 清除屏幕
draw.text((0, 0), text[:8], font=font, fill=255) # 仅显示前8个字符
disp.image(image) # 更新屏幕内容
disp.show()
屏幕显示这里进行了封装,确保每次显示前能自动清屏,同样的限制只能显示8个字符,避免超出显示长度。
动画表情绘制函数
def draw_face(mouth_state=0):
"""显示不同表情的脸部动画"""
draw.rectangle((0, 0, width, height), outline=0, fill=0) # 清空屏幕
# 绘制眼睛
draw.ellipse((32, 15, 40, 25), outline=255, fill=255) # 左眼
draw.ellipse((88, 15, 96, 25), outline=255, fill=255) # 右眼
# 嘴巴动画
if mouth_state == 0:
draw.line((50,50, 78, 50), fill=255, width=2) # 直线嘴巴
elif mouth_state == 1:
draw.arc((50, 40, 78, 60), start=0, end=180, fill=255) # 微笑嘴巴
elif mouth_state == 2:
draw.ellipse((58, 50, 70, 60), outline=255, fill=255) # 张嘴嘴巴
disp.image(image) # 更新屏幕内容
disp.show()
动画表情直接利用库函数绘制圆和弧线实现
嘴巴动画
def asr_animation():
global asr_running
frame = 0
while asr_running:
draw_face(frame % 3) # 按 0、1、2 的顺序切换嘴巴形态
frame += 1
time.sleep(0.2) # 控制动画速度
嘴巴动画通过该函数来控制变换,因为采用了多线程,可以避免动画影响Vosk识别语音
Vosk 语音识别
def recognize_speech(p):
global asr_running
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=20480)
stream.start_stream()
print("正在识别语音...")
asr_running = True # 启动动画
animation_thread = threading.Thread(target=asr_animation) # 创建动画线程
animation_thread.start()
try:
while True:
data = stream.read(2048, exception_on_overflow=False) # 读取音频数据
if recognizer.AcceptWaveform(data): # 处理音频流
result = recognizer.Result() # 获取识别结果
result_json = json.loads(result) # 解析 JSON 数据
if "text" in result_json:
text = result_json['text'] # 提取识别文本
print(f"识别到的文字: {text}")
asr_running = False # 停止动画
animation_thread.join() # 等待动画线程结束
draw_face(1) # 识别完成后显示微笑表情
time.sleep(1)
# 释放音频资源
stream.stop_stream()
stream.close()
return text
except IOError:
pass
# 释放资源
asr_running = False
animation_thread.join()
stream.stop_stream()
stream.close()
我们先配置音频采样率16kHz,然后设置了一个20480帧的缓冲区大小(约1.28s),16位PCM格式。然后配置asr_running 全局标志用于控制动画线程运行,独立线程运行asr_animation实现非阻塞式用户体验。这里循环中启用流式传输,每次读取 2048 字节(约 128ms )实现非阻塞读取:exception_on_overflow=False 允许忽略缓冲区溢出错误,这样无需等待完整录音文件,实现边录边传。
保留中文字符
def clean_text(text):
return re.sub(r"[^\u4e00-\u9fa5,。!?]", "", text)
由于我们使用的espeak-ng是轻量化的,只能支持一种语言,所以这里我们要过滤掉所以除中文外的文字和特殊符号。这里使用正则表达式"[^\u4e00-\u9fa5,。!?]"。正则表达式中的方括号表示字符集,^符号在开头表示取反,也就是匹配不在这个字符集里的任何字符。所以这个正则表达式的作用是匹配所有不属于指定Unicode范围的字符,以及标点符号,。!?。
模型处理
async def generate_and_play_text(input_text):
draw_face(1) # 显示微笑表情
time.sleep(1)
conversation_history.append({"role": "user", "content": input_text}) # 记录用户输入
response = ollama.chat(model="qwen2:0.5b", messages=conversation_history, stream=True) # AI 生成回答
generated_text = ""
for chunk in response:
if 'message' in chunk and 'content' in chunk['message']:
raw_text = chunk['message']['content']
clean_tts_text = clean_text(raw_text) # 清理文本
generated_text += raw_text
show_on_oled(raw_text)
print(f"当前生成: {generated_text}")
if clean_tts_text: # 确保有中文内容才播放
# 显示在 OLED 上
subprocess.run(['espeak-ng', '-v', 'zh', clean_tts_text]) # 语音朗读
conversation_history.append({"role": "assistant", "content": generated_text}) # 记录 AI 回应
draw_face(1) # 结束后显示微笑
time.sleep(1)
这里就是将语音识别的文字传给Ollama然后交给模型处理,使用stream=True实现流式逐块生成,然后通过for chunk in response: if 'message' in chunk and 'content' in chunk['message']:典型的流式响应处理模式,主要用于处理流式返回的数据结构
主函数
async def main():
loop = asyncio.get_event_loop() # 获取事件循环
executor = ThreadPoolExecutor(max_workers=2) # 线程池用于并发任务
p = pyaudio.PyAudio() # 创建 pyaudio 实例
while True:
recognized_text = await loop.run_in_executor(executor, recognize_speech, p) # 识别语音
await generate_and_play_text(recognized_text) # 生成回答并朗读
p.terminate() # 释放音频资源
if __name__ == "__main__":
asyncio.run(main()) # 运行主程序
这里max_workers=2 采用双线程实现动画和语音识别共同运行,互不干涉。然后通过pyaudio库用于输入音频数据,代入我们前面创建的函数中。
3D外壳结构
3D外壳由嘉立创云CAD平台构建
3D外壳工程链接-嘉立创云CAD
主体
| 侧面1 | 侧面2 |
|---|---|
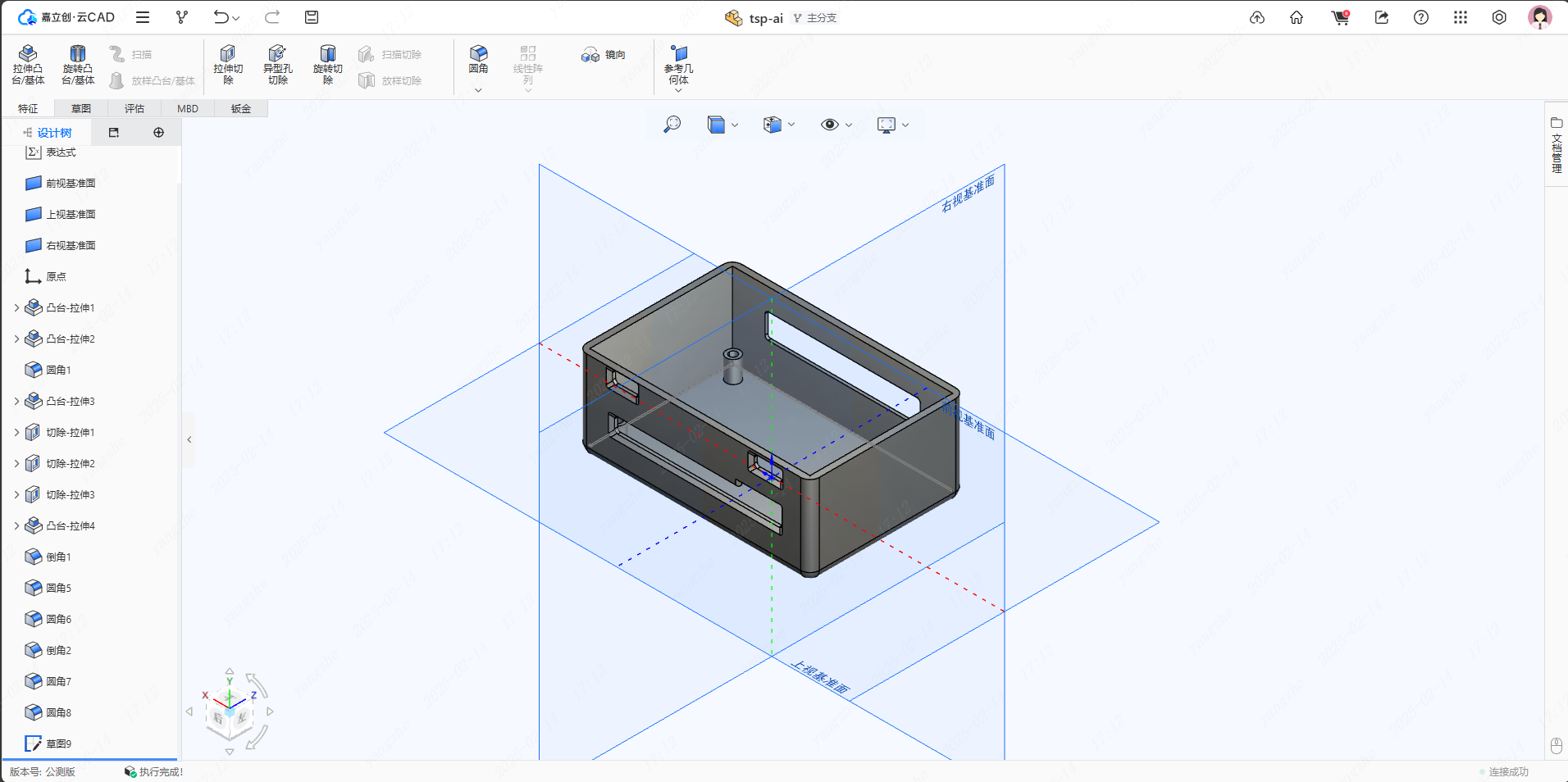 | 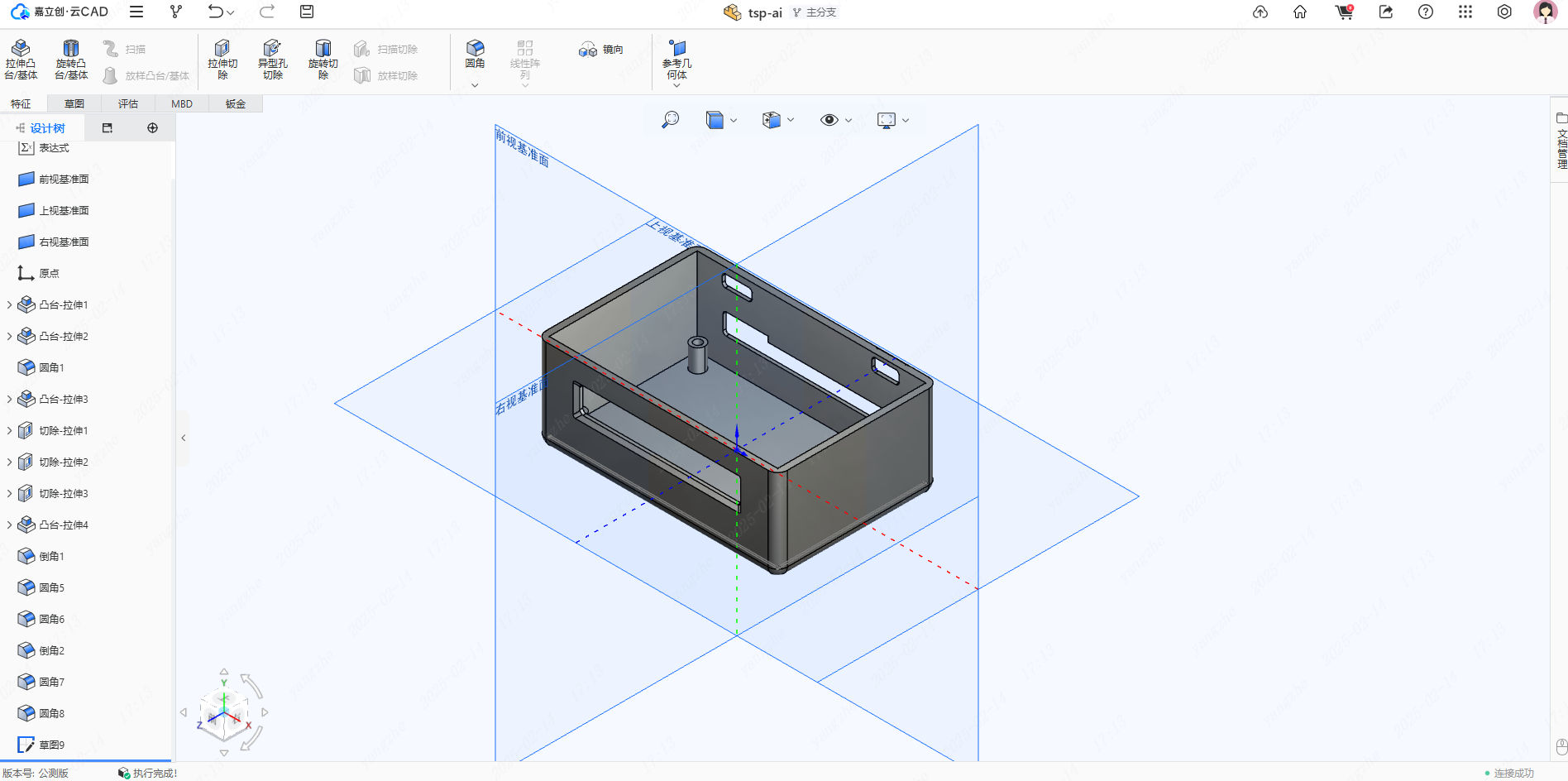 |
- 外壳设计有螺丝孔柱,用于固定,并拉高7mm,可放置40x55x5mm锂电池,并为主要接口做了开孔。
顶盖
| 正面 | 背面 |
|---|---|
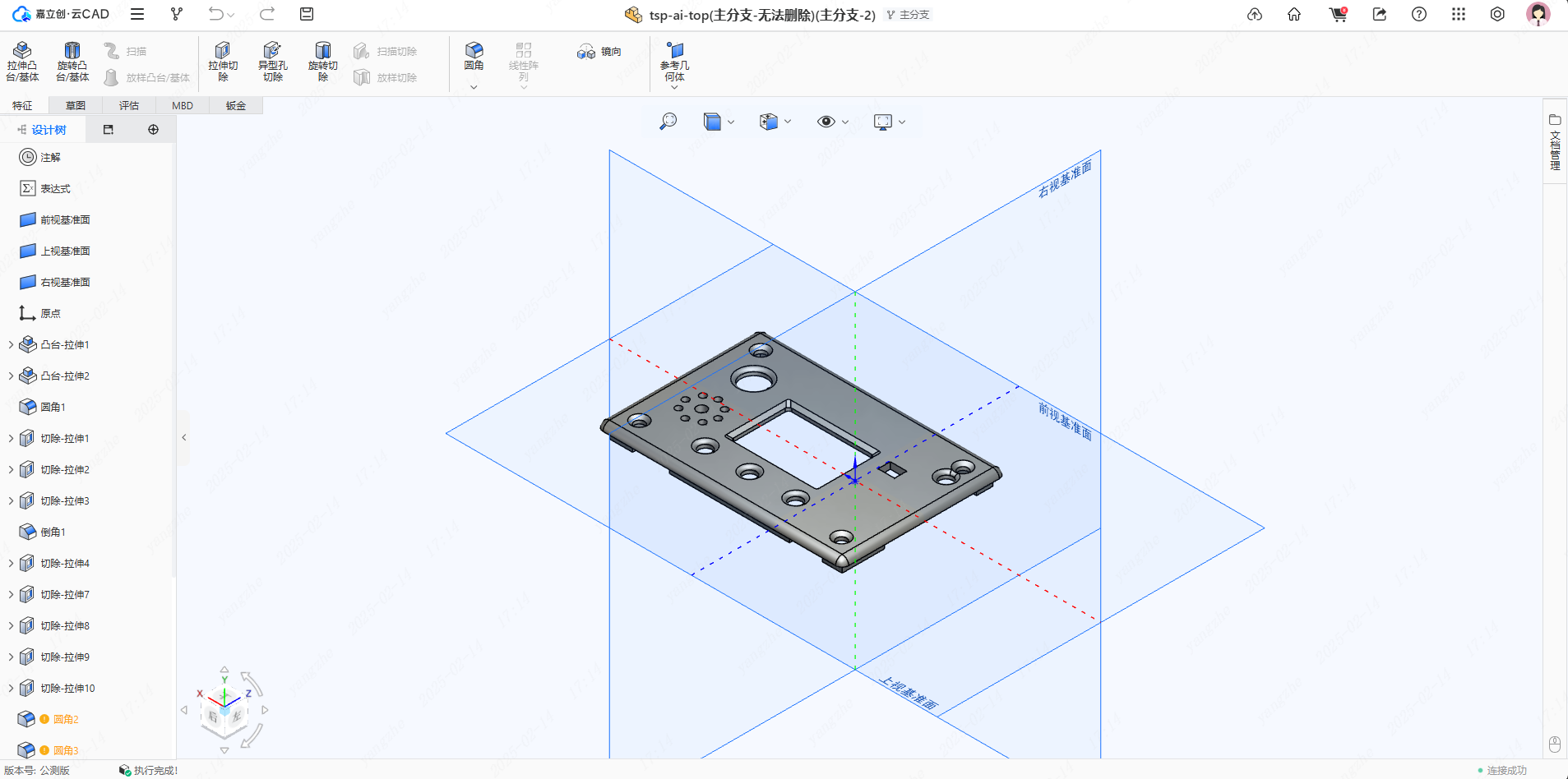 | 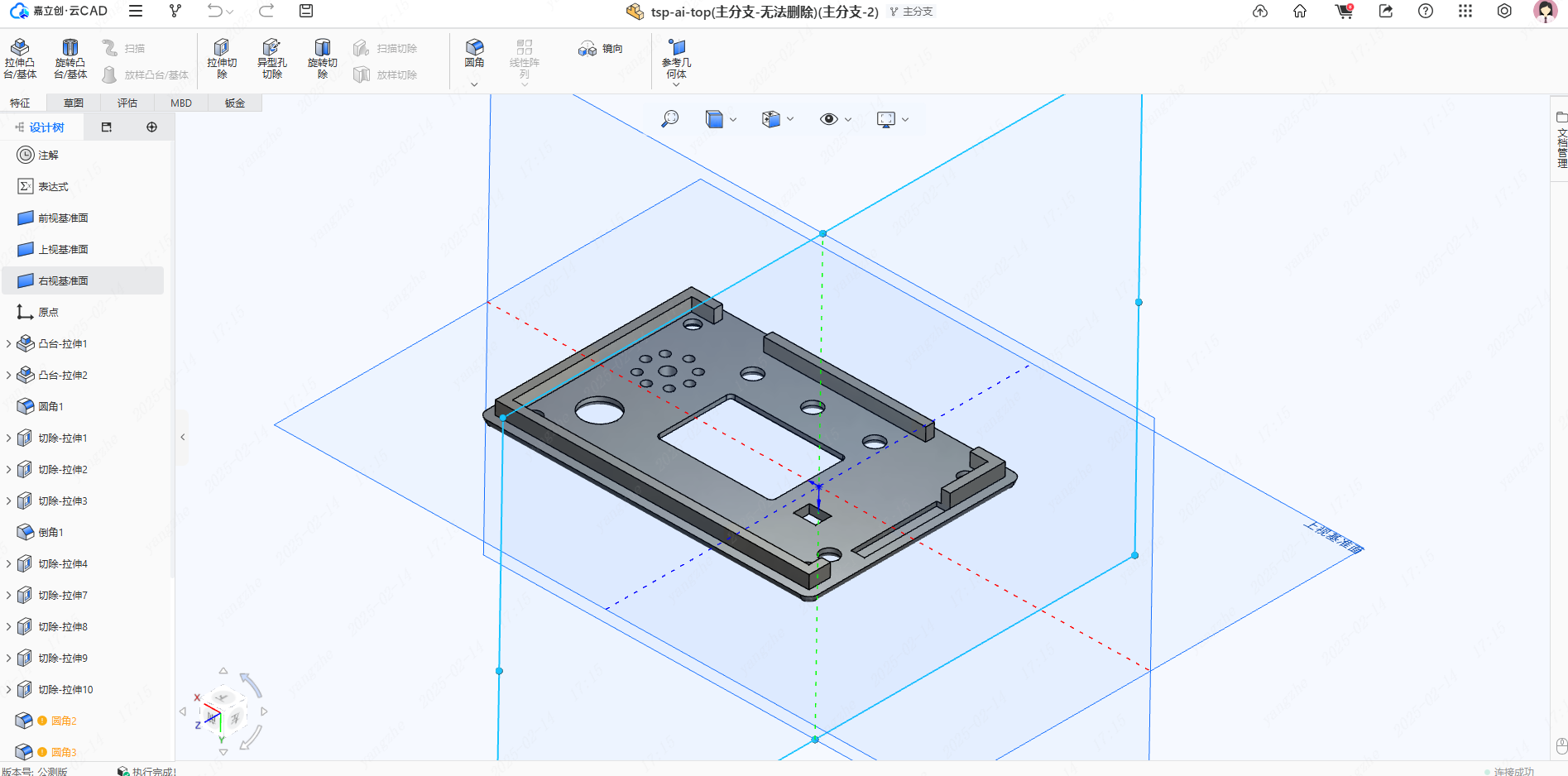 |
- 顶盖为驻极体麦克风、扬声器设计有开孔,屏幕、按键温湿度传感器均有开孔,电量指示灯切除1mm厚度增加透光性。
组装
组装较为简单,分为上中下三层
PCB

作为拓展版,泰山派IO排针对接语音助手拓展版的IO排母连接即可
上层

最上层是上壳。
中间层

中间层是电路板空间,通过上壳内的限位槽将PCB固定在中间,并压住底部电池。
下层
下层为电池空间,可以放置40x55x5mm锂电池。
按键说明

- 左键为菜单左移
- 右键为菜单右移
- 中键为确定键
- 电源键为单击开机,双击关机
功能拓展
AI-Box不仅局限于现有功能的实现,你完全可以基于现有框架进行改造,比如拓展预留的UART接口,将AI-Box打造成离线语音模块,与你的其他项目结合,实现离线大模型对话,或者使用AI-Box充当家庭控制终端,对接MQTT服务器实现家庭设备控制,再或者利用其余的IO接口打造一个智能机器人,再或者是搭配Open-CV视觉识别打造多模态机器人等等。
实物图
| 实物图1 | 实物图2 |
|---|---|
 |  |
| 表情 | 响应 |
 |  |
| 手电筒 | 温湿度 |
 |  |
注意事项
- 推荐泰山派配置为4+32G EMMC版本,如果你是其他版本也没关系,可以参考文档配置虚拟内存和挂载TF卡扩容,低内存推荐使用Qwen2 0.5B参数模型
- 资源包中提供了4份代码,包含AHT10温湿度模块测试代码,LED驱动测试代码,ai大模型对话测试代码,功能集成代码。
设计图
BOM
 克隆工程
克隆工程 暂无相关工程
暂无相关工程
评论